Introduction
Welcome to the second installment of the Advanced Octrees series. Make sure you’ve also read part one. In the second part I discuss different Octree data structure layouts. Essentially, literature distinguishes between two different layouts: the traditional layout using a pointer-based node representation and the implicit layout using an index-based node representation. Both layouts have their strong points and their weak points. Pointer-based node representations are advantageous if the Octree needs to be updated frequently and if memory consumption is not an issue. Implicit node representations pay off in memory limited applications.
Regardless of the chosen representation, the node struct always contains a pointer to the list of objects it encloses. Additionally, almost always the cell’s axis-aligned bounding box (AABB) is stored inside the node. The AABB can be stored in two different ways: either as two vectors AabbMin and AabbMax containing the AABB’s minimum and maximum corners, or as two vectors Center and HalfSize containing the AABB’s center and extent. If the Octree is cubic, all AABB sides have the same length and the storage size of the latter AABB representation can be reduced by storing HalfSize as a single float. Speedwise the center-extent representation is advantageous in most calculations (e.g. for view-frustum culling). Instead of storing the AABB inside the node, it can be recomputed while traversing the Octree. This is a memory consumption vs. compute trade-off.
All struct sizes given in the remainder of this post assume 64-bit wide pointers and the Vector3 class consisting of three 32-bit float variables. Let’s start with looking at pointer-based node representations first.
Pointer-based node representations
Standard representation
The most intuitive, pointer-based node representation consists of eight pointers to each of the eight child nodes. This representation supports on-demand allocation of nodes. On-demand allocation only allocates memory for child nodes, once an object is encountered which falls into the respective sub-cell. Some Octree implementations add pointers to the parent node for bottom-up traversals.
// standard representation (104 bytes)
struct OctreeNode
{
OctreeNode * Children[8];
OctreeNode * Parent; // optional
Object * Objects;
Vector3 Center;
Vector3 HalfSize;
};
As leaf nodes have no children, they don’t need to store child pointers. Therefore, two different node types, one for inner nodes and one for leaf nodes, can be used. To distinguish between inner nodes and leaf nodes, a flag must be stored additionally. The flag can be either stored as an additional bool variable IsLeaf, or encoded in the least significant bit of one of the pointers if the nodes are allocated with appropriate alignment (C++’s new operator usually aligns object types to the size of their largest member).
// inner node (105 bytes) // leaf node (41 bytes)
struct OctreeInnerNode struct OctreeLeafNode
{ {
OctreeInnerNode * Children[8]; // leaf has no children
OctreeInnerNode * Parent; OctreeInnerNode * Parent; // optional
Object * FirstObj; Object * Objects;
Vector3 Center; Vector3 Center;
Vector3 HalfSize; Vector3 HalfSize;
bool IsLeaf; bool IsLeaf;
}; };
Using two different node types, one for inner nodes and one for leaf nodes, can be applied as well to the following two representations.
Block representation
A significant amount of memory can be saved by storing just one pointer to a block of eight children, instead of eight pointers to eight children. That way the storage size of an inner node can be reduced from 105 bytes down to 49 bytes, which is only 47% of the original size. However, when a leaf node is subdivided always all eight children must be allocated. It’s not possible anymore to allocate child nodes on-demand, once the first object falling into the octant in question is encountered. Look at the following figure for an illustration of the block representation.

The corresponding code for the node struct is:
// block representation (49 bytes)
struct OctreeNode
{
OctreeNode * Children;
OctreeNode * Parent; // optional
Object * FirstObj;
Vector3 Center;
Vector3 HalfSize;
bool IsLeaf;
};
Sibling-child representation
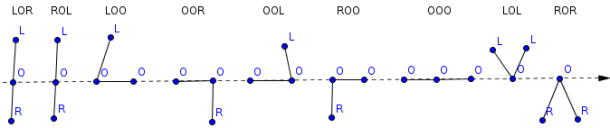
On-demand allocation can reduce the amount of required memory for nodes significantly if the world is sparsely populated and thereby, many octants contain no objects. A trade-off between the standard representation and the block representation is the so called sibling-child representation. This representation allows on-demand allocation while storing only two node pointers per node instead of eight. The first pointer is NextSibling, which points to the next child node of the node’s parent. The second pointer is FirstChild, which points to the node’s first child node. Look at the following figure for an illustration of the sibling-child representation. Compare the number of required pointers per node to the standard representation.

In comparison to the standard representation, the sibling-child representation needs only 25% of the memory for pointers (two instead of eight pointers). As long as the child nodes are accessed sequentially the two representations perform equally well. However, accessing nodes randomly requires dereferencing on average four times more pointers. The code for the node struct is given below.
// sibling-child representation (56 bytes)
struct OctreeNode
{
OctreeNode * NextSibling;
OctreeNode * FirstChild;
OctreeNode * Parent; // optional
Object * FirstObj;
Vector3 Center;
Vector3 HalfSize;
};
Comparison
The choice of the right pointer-based representation depends mainly on the importance of memory usage vs. traversal speed. Explicitly storing all eight child pointers wastes memory but makes traversing and modifying the Octree easy to implement and fast. In contrast, the sibling-child representation saves 50% memory as a single node is only 48 bytes instead of 92 bytes. However, the additional pointer indirections might complicate the traversal code and make it slower. It can be a good trade-off to store just a single pointer to a block of eight sub-cells. This representation needs only 40 bytes of memory per node and the traversal code is as easy as in the representation with eight child pointers. However, always allocating all eight sub-cells can waste memory in sparsely populated worlds with many empty sub-cells.
Implicit node representations
Linear (hashed) Octrees
Linear Octrees [Gargantini, 1982]1, originally proposed for Quadtrees, combine the advantages of pointer-based and pointer-less representations. Linear Octrees provide easy and efficient access to parent and child nodes, even though no explicit tree structure information must be stored per node.
Overview
Instead of child and parent pointers, Linear Octrees store a unique index called locational code in each node. Additionally, all Octree nodes are stored in a hash map which allows directly accessing any node based on its locational code. The locational code is constructed in such a way, that deriving the locational codes for any node’s parent and children based on its own locational code is feasible and fast. To avoid unnecessary hash map look-ups for children which don’t exist, the node struct can be extended by a bit-mask indicating which children have been allocated and which haven’t.
struct OctreeNode // 13 bytes
{
Object * Objects;
uint32_t LocCode; // or 64-bit, depends on max. required tree depth
uint8_t ChildExists; // optional
};
The locational code
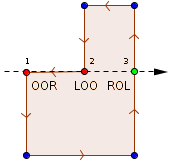
In order to create the locational code each octant gets a 3-bit number between 0 and 7 assigned, depending on the node’s relative position to it’s parent’s center. The possible relative positions are: bottom-left-front (000), bottom-right-front (001), bottom-left-back (010), bottom-right-back (011), top-left-front (100), top-right-front (101), top-left-back (110), top-right-back (111). The locational code of any child node in the tree can be computed recursively by concatenating the octant numbers of all the nodes from the root down to the node in question. The octant numbers are illustrated in the figure below.

The AABB of the node can be stored explicitly as before, or it can be computed from the node’s tree depth stored implicitly inside the locational code. To derive the tree depth at a node from its locational code a flag bit is required to indicate the end of the locational code. Without such a flag it wouldn’t be possible to distinguish e.g. between 001 and 000 001. By using a 1 bit to mark the end of the sequence 1 001 can be easily distinguished from 1 000 001. Using such a flag is equivalent to setting the locational code of the Octree root to 1. With one bit for the flag and three bits per Octree level, a 32-bit locational code can represent at maximum a tree depth of 10, a 64-bit locational code a tree depth of 21. Given the locational code  of a node, its depth in the Octree can be computed as
of a node, its depth in the Octree can be computed as 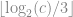 . An efficient implementation using bit scanning intrinsics is given below for GCC and Visual C++.
. An efficient implementation using bit scanning intrinsics is given below for GCC and Visual C++.
size_t Octree::GetNodeTreeDepth(const OctreeNode *node)
{
assert(node->LocCode); // at least flag bit must be set
// for (uint32_t lc=node->LocCode, depth=0; lc!=1; lc>>=3, depth++);
// return depth;
#if defined(__GNUC__)
return (31-__builtin_clz(node->LocCode))/3;
#elif defined(_MSC_VER)
long msb;
_BitScanReverse(&msb, node->LocCode);
return msb/3;
#endif
}
When sorting the nodes by locational code the resulting order is the same as the pre-order traversal of the Octree, which in turn is equivalent to the Morton Code (also known as Z-Order Curve). The Morton Code linearly indexes multi-dimensional data, preserving data locality on multiple levels.
Tree traversal
Given the locational code, moving further down or up the Octree is a simple two-step operation consisting of (1) deriving the locational code of the next node and (2) looking-up the node in the hash-map.
For traversing up the Octree, first, the locational code of the parent node must be determined. This is done by removing the least significant three bits of the locational code of the current node. Now, the parent node can be retrieved by doing a hash map look-up with the previously computed locational code. An exemplary implementation is given below.
class Octree
{
public:
OctreeNode * GetParentNode(OctreeNode *node)
{
const uint32_t locCodeParent = node->LocCode>>3;
return LookupNode(locCodeParent);
}
private:
OctreeNode * LookupNode(uint32_t locCode)
{
const auto iter = Nodes.find(locCode);
return (iter == Nodes.end() ? nullptr : &(*iter));
}
private:
std::unordered_map<uint32_t, OctreeNode> Nodes;
};
For traversing down the Octree, first, the locational code of the child in question must be computed. This is done by appending the octant number of the child to the current node’s locational code. After that the child node can be retrieved by doing a hash map look-up with the previously computed locational code. The following code visits all nodes of an Octree from the root down to the leafs.
void Octree::VisitAll(OctreeNode *node)
{
for (int i=0; i<8; i++)
{
if (node->ChildExists&(1<<i))
{
const uint32_t locCodeChild = (node->LocCode<<3)|i;
const auto *child = LookupNode(locCodeChild);
VisitAll(child);
}
}
}
Full Octrees
In a full or complete Octree, every internal node has eight children and all leaf nodes have exactly the same tree depth  which is fixed a priori. A full Octree has
which is fixed a priori. A full Octree has  leaf nodes. Thus, it’s equal to a regular 3D grid with a resolution of
leaf nodes. Thus, it’s equal to a regular 3D grid with a resolution of 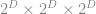 . The total number of tree nodes can be computed as
. The total number of tree nodes can be computed as  . Full Octrees of four successive subdivision levels are depicted in the figure below.
. Full Octrees of four successive subdivision levels are depicted in the figure below.

Thanks to the regularity of a full Octree it can be implemented without explicitly storing any tree structure and cell size information in the nodes. Hence, a single node consists solely of the pointer to the objects; which is eight bytes on a 64-bit machine. Similar to binary trees, full Octrees can be stored pointer-less in an array FullOctreeNode Nodes[K] (zero-based). The children of any node Nodes[i] can be found at Nodes[8*i+1] to Nodes[8*i+8], the parent of node Nodes[i] can be found at Nodes[floor((i-1)/8)] if i is not the root node ( ).
).
The most common application of full Octrees are non-sparse, static scenes with very evenly distributed geometry. If not most of the nodes contain objects, memory savings due to small node structs are quickly lost by the huge amount of nodes that need to be allocated. A full Octree of depth  consists of
consists of  (1.2 billion) nodes which consume around 9.14 GiB of memory.
(1.2 billion) nodes which consume around 9.14 GiB of memory.
Wrap up
Which node representation to choose for an Octree implementation depends mainly on the application. There are three major aspects that can help deciding on the representation.
- How much data will supposedly be stored in the Octree? Is the reduced node size of an implicit node representation crucial for keeping the memory usage in check?
- Will the Octree be subject to frequent changes? Pointer-based node representations are much more suitable for modifying Octrees than implicit node representations.
- Will the Octree be sparsely or densely populated? How much memory can be saved by supporting on-demand allocation of nodes? Is maybe a full Octree suitable?









 points. As described in the previous section, each of the points can only fall exactly into one node. Is it possible to establish a relation between the number of points
points. As described in the previous section, each of the points can only fall exactly into one node. Is it possible to establish a relation between the number of points  ? It turns out, that the number of Octree nodes (=> the Octree depth) is not limited by the number of points. The reason is, that if the points are distributed closely enough in multiple widespread clusters, the number of Octree nodes can grow arbitrarily large. Look at the following figure for an illustration.
? It turns out, that the number of Octree nodes (=> the Octree depth) is not limited by the number of points. The reason is, that if the points are distributed closely enough in multiple widespread clusters, the number of Octree nodes can grow arbitrarily large. Look at the following figure for an illustration.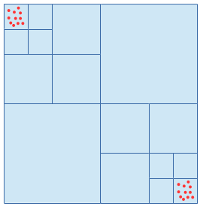
 between any two points in the point set and the side length of the root cell
between any two points in the point set and the side length of the root cell  , it can be shown that the maximum Octree depth is limited by
, it can be shown that the maximum Octree depth is limited by  . The following proof for this upper bound is rather simple.
. The following proof for this upper bound is rather simple.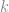 is given by
is given by  . Any inner node encloses at least two points, otherwise it would be a leaf node. Hence, the maximum distance between any two points in this cell is guaranteed to be bigger than the minimum distance
. Any inner node encloses at least two points, otherwise it would be a leaf node. Hence, the maximum distance between any two points in this cell is guaranteed to be bigger than the minimum distance  .
. – and
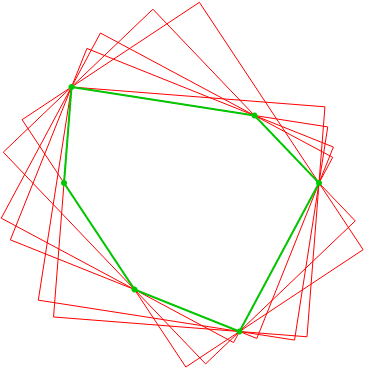
– and  – coordinates of its vertices. Such an axis aligned bounding box (AABB) can be computed trivially but it’s in most cases significantly bigger than the polygon’s OMBB. Finding the OMBB requires some more work as the bounding box’ area must be minimized, constrained by the location of the polygon’s vertices. Look at the following figure for an illustration (AABB in blue, OMBB in red).
– coordinates of its vertices. Such an axis aligned bounding box (AABB) can be computed trivially but it’s in most cases significantly bigger than the polygon’s OMBB. Finding the OMBB requires some more work as the bounding box’ area must be minimized, constrained by the location of the polygon’s vertices. Look at the following figure for an illustration (AABB in blue, OMBB in red).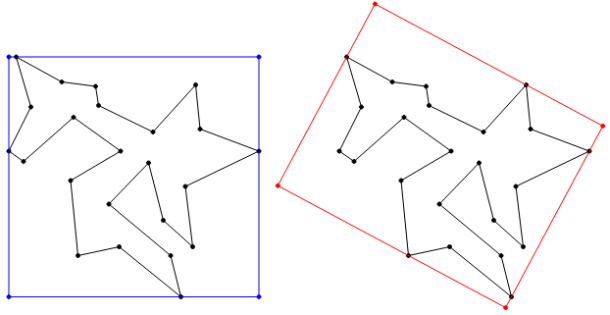
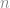 points can be described as the closed polygonal chain of all outer points of the set, which entirely encloses all set elements. You can picture it as the shape of a rubber band stretched around all set elements. The convex hull of a set of two-dimensional points can be efficiently computed in
points can be described as the closed polygonal chain of all outer points of the set, which entirely encloses all set elements. You can picture it as the shape of a rubber band stretched around all set elements. The convex hull of a set of two-dimensional points can be efficiently computed in  . In the figure below the convex hull of the vertices of a concave polygon is depicted.
. In the figure below the convex hull of the vertices of a concave polygon is depicted.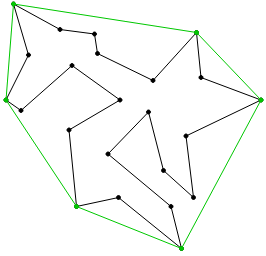
 , where
, where  is the number of vertices in the convex hull. In the general case Gift Wrapping is outperformed by other algorithms. Especially, when all points are part of the convex hull. In that case the complexity degrades to
is the number of vertices in the convex hull. In the general case Gift Wrapping is outperformed by other algorithms. Especially, when all points are part of the convex hull. In that case the complexity degrades to  .
.
 and
and  of the convex hull.
of the convex hull. and
and  and two horizontal ones at
and two horizontal ones at  and
and  .
. .
. of the current rectangle.
of the current rectangle. .
. between each caliper line and its associated, following convex hull edge is determined. Then, all caliper lines are rotated at once by
between each caliper line and its associated, following convex hull edge is determined. Then, all caliper lines are rotated at once by 