Introduction
Welcome to part four of the the Advanced Octrees series. Here you can find part one, two and three. In this part I show you how to access neighbor nodes in Quadtrees. The algorithm can be naturally extended to Octrees, but it’s easier to understand and code in just two dimensions. Neighbors are such nodes that either share an edge in horizontal (west, east) or vertical (north, south) direction, or that share a vertex in one of the four diagonal directions (north-west, north-east, south-west, south-east). See the figure below for an illustration. The node of which we want to find the neighbors is colored green. In the following this node is called source node. The neighbor nodes are colored red and labeled with the corresponding direction.

In the literature Quadtree neighbor finding algorithms are distinguished by two properties:
- Does the algorithm operate on pointer-based Quadtrees or on linear Quadtrees? Read up on different Quadtree representations in part two of this series. The algorithm discussed in this post is based on a pointer representation.
- Can the algorithm only find neighbors of equal or greater size, or can it also find neighbors of smaller size. We’ll see later that finding neighbors of smaller size is somewhat harder. Greater / equal / smaller refers to the difference in tree level between the source node and the neighbor nodes.
The figure below shows examples of neighbor relationships in north direction between nodes on different tree levels. Note, that a node can have more than one neighbor per direction if the sub-tree on the other side of the north edge is deeper than the sub-tree of the source node.

Algorithm
The input to the algorithm is a direction and an arbitrary Quadtree node (inner of leaf). The output is a list of neighbor nodes in the given direction. The neighbors can be of greater size, equal size or smaller size (see previous figure). The algorithm is symmetric with respect to the direction. That’s why I only show an implementation for the north direction. It should be easy to extend the implementation to the other seven directions.
The neighbor finding happens in two steps. In step 1 we search for a neighbor node of greater or equal size (yellow). If such a node can be found we perform the second step, in which we traverse the sub-tree of the neighbor node found in step 1 to find all neighbors of smaller size. The two steps are illustrated in the figure below.

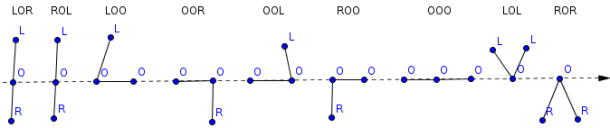
So how to find the neighbor of greater or equal size? Starting from the source node the algorithm traverses up the tree as long as the current node is not a south child of the parent, or the root is reached. After that the algorithm unrolls the recursion descending downwards always picking the south node. The node the recursion stops at is the north neighbor of the source node. This node is always on the same tree level as the source node, or further up the tree. Because the source node can be in the west or in the east, there’s a case distinction necessary to handle both possibilities.
Below is an implementation in Python. The code uses a pointer based Quadtree data structure, in which every node consists of a parent and four children. The children array is indexed using the constants NW, NE, SW and SE. The full code can be found on Github.
def get_neighbor_of_greater_or_equal_size(self, direction):
if direction == self.Direction.N:
if self.parent is None: # Reached root?
return None
if self.parent.children[self.Child.SW] == self: # Is 'self' SW child?
return self.parent.children[self.Child.NW]
if self.parent.children[self.Child.SE] == self: # Is 'self' SE child?
return self.parent.children[self.Child.NE]
node = self.parent.get_neighbor_of_greater_or_same_size(direction)
if node is None or node.is_leaf():
return node
# 'self' is guaranteed to be a north child
return (node.children[self.Child.SW]
if self.parent.children[self.Child.NW] == self # Is 'self' NW child?
else node.children[self.Child.SE])
else:
# TODO: implement symmetric to NORTH case
In step 2 we use the neighbor node obtained in step 1 to find neighbors of smaller size by recursively descending the tree in south direction until we reach the leaf nodes. On the way we always keep both, the south west and the south east node, because any node lower in the tree than the neighbor node from step 2 is smaller than the source node and therefore a neighbor candidate.
def find_neighbors_of_smaller_size(self, neighbor, direction):
candidates = [] if neighbor is None else [neighbor]
neighbors = []
if direction == self.Direction.N:
while len(candidates) > 0:
if candidates[0].is_leaf():
neighbors.append(candidates[0])
else:
candidates.append(candidates[0].children[self.Child.SW])
candidates.append(candidates[0].children[self.Child.SE])
candidates.remove(candidates[0])
return neighbors
else:
# TODO: implement other directions symmetric to NORTH case
Finally, we combine the functions from step 1 and 2 to get the complete neighbor finding function.
def get_neighbors(self, direction): neighbor = self.get_neighbor_of_greater_or_equal_size(direction) neighbors = self.find_neighbors_of_smaller_size(neighbor, direction) return neighbors
Complexity
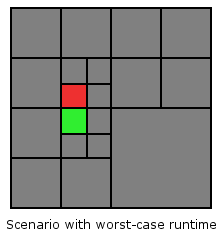
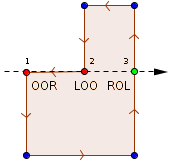
The complexity of this algorithm is bounded by the depth of the Quadtree. In the worst-case the source node and its neighbors are on the last tree level but their first common ancestor is only the root node. This is the case for any node that lies directly below/above or left/right of the line splitting the root node horizontally/vertically. See the following picture for an illustration.







 of a node, its depth in the Octree can be computed as
of a node, its depth in the Octree can be computed as 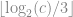 . An efficient implementation using bit scanning intrinsics is given below for GCC and Visual C++.
. An efficient implementation using bit scanning intrinsics is given below for GCC and Visual C++. which is fixed a priori. A full Octree has
which is fixed a priori. A full Octree has  leaf nodes. Thus, it’s equal to a regular 3D grid with a resolution of
leaf nodes. Thus, it’s equal to a regular 3D grid with a resolution of 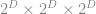 . The total number of tree nodes can be computed as
. The total number of tree nodes can be computed as  . Full Octrees of four successive subdivision levels are depicted in the figure below.
. Full Octrees of four successive subdivision levels are depicted in the figure below.
 ).
). consists of
consists of  (1.2 billion) nodes which consume around 9.14 GiB of memory.
(1.2 billion) nodes which consume around 9.14 GiB of memory.
 points. As described in the previous section, each of the points can only fall exactly into one node. Is it possible to establish a relation between the number of points
points. As described in the previous section, each of the points can only fall exactly into one node. Is it possible to establish a relation between the number of points  ? It turns out, that the number of Octree nodes (=> the Octree depth) is not limited by the number of points. The reason is, that if the points are distributed closely enough in multiple widespread clusters, the number of Octree nodes can grow arbitrarily large. Look at the following figure for an illustration.
? It turns out, that the number of Octree nodes (=> the Octree depth) is not limited by the number of points. The reason is, that if the points are distributed closely enough in multiple widespread clusters, the number of Octree nodes can grow arbitrarily large. Look at the following figure for an illustration.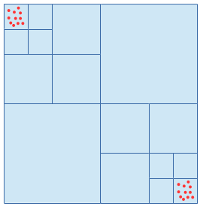
 between any two points in the point set and the side length of the root cell
between any two points in the point set and the side length of the root cell  , it can be shown that the maximum Octree depth is limited by
, it can be shown that the maximum Octree depth is limited by  . The following proof for this upper bound is rather simple.
. The following proof for this upper bound is rather simple. is given by
is given by  . Any inner node encloses at least two points, otherwise it would be a leaf node. Hence, the maximum distance between any two points in this cell is guaranteed to be bigger than the minimum distance
. Any inner node encloses at least two points, otherwise it would be a leaf node. Hence, the maximum distance between any two points in this cell is guaranteed to be bigger than the minimum distance  .
. – and
– and  – coordinates of its vertices. Such an axis aligned bounding box (AABB) can be computed trivially but it’s in most cases significantly bigger than the polygon’s OMBB. Finding the OMBB requires some more work as the bounding box’ area must be minimized, constrained by the location of the polygon’s vertices. Look at the following figure for an illustration (AABB in blue, OMBB in red).
– coordinates of its vertices. Such an axis aligned bounding box (AABB) can be computed trivially but it’s in most cases significantly bigger than the polygon’s OMBB. Finding the OMBB requires some more work as the bounding box’ area must be minimized, constrained by the location of the polygon’s vertices. Look at the following figure for an illustration (AABB in blue, OMBB in red).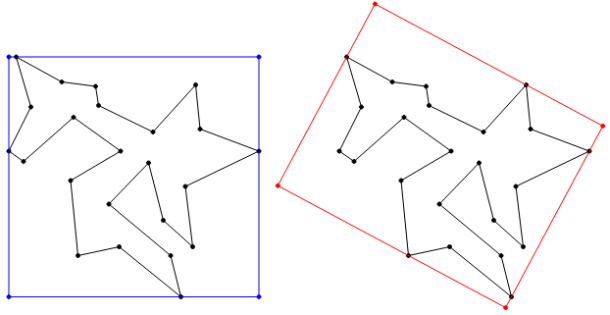
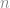 points can be described as the closed polygonal chain of all outer points of the set, which entirely encloses all set elements. You can picture it as the shape of a rubber band stretched around all set elements. The convex hull of a set of two-dimensional points can be efficiently computed in
points can be described as the closed polygonal chain of all outer points of the set, which entirely encloses all set elements. You can picture it as the shape of a rubber band stretched around all set elements. The convex hull of a set of two-dimensional points can be efficiently computed in  . In the figure below the convex hull of the vertices of a concave polygon is depicted.
. In the figure below the convex hull of the vertices of a concave polygon is depicted.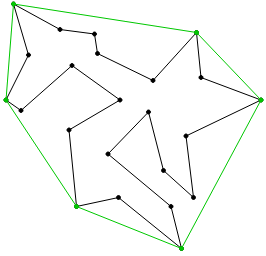
 , where
, where  is the number of vertices in the convex hull. In the general case Gift Wrapping is outperformed by other algorithms. Especially, when all points are part of the convex hull. In that case the complexity degrades to
is the number of vertices in the convex hull. In the general case Gift Wrapping is outperformed by other algorithms. Especially, when all points are part of the convex hull. In that case the complexity degrades to  .
.
 and
and  of the convex hull.
of the convex hull. and
and  and two horizontal ones at
and two horizontal ones at  and
and  .
. .
. of the current rectangle.
of the current rectangle. .
. between each caliper line and its associated, following convex hull edge is determined. Then, all caliper lines are rotated at once by
between each caliper line and its associated, following convex hull edge is determined. Then, all caliper lines are rotated at once by 

