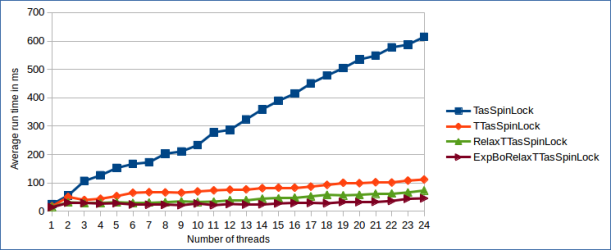
Last time we saw that spinlock implementations which only use a single synchronization variable (Test-And-Set Lock, Ticket Lock) don’t scale with growing numbers of threads. Today, I want to talk about two spinlock variants that scale. Namely the Graunke and Thakkar Lock1 (1989) and the Anderson Lock2 (1990). Their underlying key idea is to use one synchronization variable per thread instead of one for all threads, to reduce the amount of cache line invalidations when acquiring/releasing the lock. Both spinlock variants store the synchronization variables in an array. This means that there’s an upper bound on the maximum number of thread’s that can compete for the lock concurrently, which must be known a priori. In upcoming blog posts I’m going to show spinlock variants (the MCS Lock and the CLH Lock) that improve upon array-based spinlocks by removing this hard upper limit.
Anderson’s lock
Anderson’s spinlock is basically a FIFO queue of threads. It’s implemented as an array, which is accessed via an atomic ring-buffer-style index counter. Hence, it requires an atomic fetch-and-add (std::atomic::fetch_add in C++11) operation to advance the ring-buffer index. The basic idea is that each thread spins on its own synchronization variable while it’s = true. The synchronization variable of the next thread in line is eventually set to false when the previous thread leaves the critical section (CS).
Below is an implementation of Anderson’s spinlock in C++11. Note, that this implementation is for illustrative purpose only. It’s not optimized for performance. The array of synchronization variables LockedFlags is initially set to [false, true, true, ..., true]. The first element is set to false, so that the very first thread in line can enter the critical section: for the first thread there’s no previous thread which can enable the first thread to enter the CS. After successfully entering the CS the synchronization variable is false and needs to be reset to true for future threads. It must be taken care for that NextFreeIdx doesn’t overflow. If the maximum number of threads is a power-of-2 integer arithmetic will just work fine, because the overflow matches up with the modulo computation. Otherwise, NextFreeIdx must be kept in check to avoid overflows.
Anderson’s lock requires 


class AndersonSpinLock
{
public:
AndersonSpinLock(size_t maxThreads=std::thread::hardware_concurrency()) :
LockedFlags(maxThreads)
{
for (auto &flag : LockedFlags)
flag.first = true;
LockedFlags[0].first = false;
}
ALWAYS_INLINE void Enter()
{
const size_t index = NextFreeIdx.fetch_add(1)%LockedFlags.size();
auto &flag = LockedFlags[index].first;
// Ensure overflow never happens
if (index == 0)
NextFreeIdx -= LockedFlags.size();
while (flag)
CpuRelax();
flag = true;
}
ALWAYS_INLINE void Leave()
{
const size_t idx = NextServingIdx.fetch_add(1);
LockedFlags[idx%LockedFlags.size()].first = false;
}
private:
using PaddedFlag = std::pair<std::atomic_bool,
uint8_t[CACHELINE_SIZE-sizeof(std::atomic_bool)]>;
static_assert(sizeof(PaddedFlag) == CACHELINE_SIZE, "");
alignas(CACHELINE_SIZE) std::vector<PaddedFlag> LockedFlags;
alignas(CACHELINE_SIZE) std::atomic_size_t NextFreeIdx = {0};
alignas(CACHELINE_SIZE) std::atomic_size_t NextServingIdx = {1};
};
Graunke and Thakkar’s lock
In contrast to Anderson’s ring-buffer-based lock, Graunke and Thakkar use a linked list to establish a FIFO queue of threads attempting to acquire the lock. Hence, an atomic fetch-and-store operation (std::atomic::exchange in C++11) is needed to atomically update the tail of the queue. Like Anderson’s lock, every thread spins on a different synchronization variable to reduce cache traffic due to cache line invalidations. A thread trying to enter the CS spins on the synchronization variable of the thread in line before it-self by looking at the tail pointer of the wait queue. Every thread is responsible for flipping its synchronization variable when it leaves the CS, which in turn enables the next thread in line to enter.
Below is an implementation of Graunke and Thakkar’s spinlock in C++11. Note, that this implementation is for illustrative purpose only. It’s neither optimized for performance, nor does it work if threads are recreated because of how thread indices are assigned. In their original implementation – which is reflected below – the synchronization flag is not reset after successfully entering the CS. That’s why additionally the old value of the flag must be stored along with the flag pointer in the queue. The spin loop compares the current flag value with the old flag value to see if the previous thread in line has already unlocked the CS by flipping its synchronization variable. The approach used in Anderson’s lock would simplify the code significantly: the old flag value wouldn’t have to be stored anymore in the tail, which means we could get rid of all the binary arithmetic to crunch in and extract the old flag value from the tail.
Graunke and Thakkar’s lock requires
class GraunkeAndThakkarSpinLock
{
public:
GraunkeAndThakkarSpinLock(size_t maxThreads=std::thread::hardware_concurrency()) :
LockedFlags(maxThreads)
{
for (auto &flag : LockedFlags)
flag.first = 1;
assert(Tail.is_lock_free());
Tail = reinterpret_cast(&LockedFlags[0].first);
// Make sure there's space to store the old flag value in the LSB
assert((Tail&1) == 0);
}
ALWAYS_INLINE void Enter()
{
// Create new tail by chaining my synchronization variable into the list
const auto &newFlag = LockedFlags[GetThreadIndex()].first;
const auto newTail = reinterpret_cast(&newFlag)|static_cast(newFlag);
const auto ahead = Tail.exchange(newTail);
// Extract flag and old value of previous thread in line,
// so that we can wait for its completion
const auto *aheadFlag = reinterpret_cast(ahead&(~static_cast(1)));
const auto aheadValue = static_cast(ahead&1);
// Wait for previous thread in line to flip my synchronization variable
while (aheadFlag->load() == aheadValue)
CpuRelax();
}
ALWAYS_INLINE void Leave()
{
// Flipping synchronization variable enables next thread in line to enter CS
auto &flag = LockedFlags[GetThreadIndex()].first;
flag = !flag;
}
private:
ALWAYS_INLINE size_t GetThreadIndex() const
{
static std::atomic_size_t threadCounter = {0};
thread_local size_t threadIdx = threadCounter++;
assert(threadIdx < LockedFlags.size());
return threadIdx;
}
private:
using PaddedFlag = std::pair<std::atomic_uint16_t,
uint8_t[CACHELINE_SIZE-sizeof(std::atomic_uint16_t)]>;
static_assert(sizeof(PaddedFlag) == CACHELINE_SIZE, "");
// In the LSB the old value of the flag is stored
alignas(CACHELINE_SIZE) std::atomic<uintptr_t> Tail;
alignas(CACHELINE_SIZE) std::vector<PaddedFlag> LockedFlags;
static_assert(sizeof(decltype(LockedFlags)::value_type) > 1,
"Flag size > 1 required: thanks to alignment, "\
"old flag value can be stored in LSB");
};
Comparison
The major difference between Anderson’s and Graunke and Thakkar’s spinlock implementations is how synchronization variables are assigned to threads. In Graunke and Thakkar’s lock there’s a 1:1 mapping from synchronization variables to threads. Always the same synchronization variable is assigned to the same thread. As a consequence the lock can be implemented in such a way that synchronization variables are stored in memory locations local to the spinning thread. This allows the lock to perform well on even on cache-less NUMA machines.
In contrast, Anderson’s lock has no control over the memory location in which a thread’s synchronization variable is stored. The synchronization variable assigned to a thread only depends on the order in which threads attempt to acquire the lock. Therefore, the Anderson lock performs much worse on cache-less machines, because it’s entirely possible that a thread spins on a synchronization variable in a remote memory location. On all modern mainstream CPUs this difference has marginal effect, because the CPUs have caches into which the synchronization variables can migrate during spinning.
- G. Graunke, S. Thakkar. Synchronization Algorithms for Shared-Memory Multiprocessors. IEEE Computer, Vol. 23, No. 6, (1990), pp. 60-69 ↩
- T. E. Anderson. The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors. IEEE Transactions on Parallel and Distributed Systems, Vol. 1, No. 1. (1990), pp. 6-16 ↩