Typically, when a thread tries to acquire an already locked mutex it will go to sleep and give up its time slice, allowing another thread to run immediately instead. If the duration for which the mutex is held is extremely short, the time for putting the waiting thread to sleep and waking it up again to retry can easily be longer. In such cases spinlocks can be used to increase performance, by continuously trying to acquire the lock without sleeping. Side note: Obviously, it makes no sense to use spinlocks in systems with a single CPU core. Polling for the spinlock to become available would only prevent the single available CPU core from running the other thread to release the lock.
To deep dive into the multitude of spinlock implementations, it’s crucial to understand what their key characteristics are. Generally, spinlocks can be grouped into fair and unfair as well as scalable and unscalable implementations. In addition, we look at the spinlock’s memory footprint. The three properties are discussed in more detail in the rest of this post.
For all the nitty-gritty architectural details of concrete C++11 spinlock implementations read the upcoming blog posts about Test-And-Set (TAS) Locks, Ticket Locks and MCS Locks. I’ll upload the source code to this Github repository.
Scalability
Existing spinlock variants have very different performance characteristics under contention. A lock is said to be contented when there are multiple threads concurrently trying to acquire the lock while it’s taken. The performance of unscalable spinlock implementations degrades as the number of threads trying to acquire the lock concurrently goes up. The performance of simple Ticket or TAS Locks for example drops exponentially with increasing numbers of threads. In contrast, scalable spinlock implementations – like e.g. the MCS Lock – exhibit no degradation in performance even for large numbers of threads. The scalability graph of the optimal spinlock vs the Ticket Lock is depicted in the graph below.
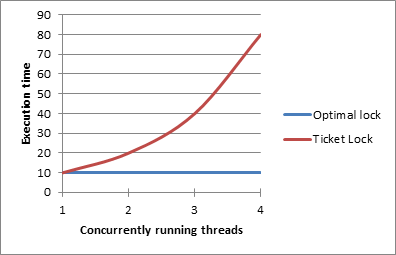
Crucial for the scalability of spinlocks is the amount of cache line invalidations which take place when the lock is acquired and released. Cache line invalidations take place when e.g. a thread modifies a synchronization variable while leaving a critical section (CS) on which other threads are polling at the same time. Suddenly, cache line copies stored in caches of other CPU cores are not valid anymore. Accordingly, these cache lines must be invalidated and reobtained from the CPU core’s cache which modified it. Thus, the number of cache line invalidations which occur when the spinlock is acquired/released is often used as a metric to compare spinlock implementations with each other. Usually, scalable spinlocks require O(1) many cache line invalidations to acquire/release the lock, while unscalable spinlocks require O(#threads) many.
Advanced scalable spinlock implementations may not only take the total number of CPU cores in a system into account, but also the details of the underlying cache coherency mechanism. For example in systems with multiple CPUs and non-uniform memory access times (NUMA), inter-core communication costs may vary greatly. For example in a NUMA system with multiple multi-core CPUs it’s entirely possible to pass a lock to another core within in the same CPU in less time than to a core of another CPU.
Fairness
Fair spinlocks guarantee that the same thread may never reacquire the lock if there are other threads trying to acquire the same lock at the same time. Fair spinlocks maintain a first-in-first-out (FIFO) order among the threads attempting to acquire the lock.
Often, unfair spinlocks trade latency for throughput, while fair spinlocks trade throughput for latency. Consider the following example. Let’s say we’re running t threads each performing n/t loop iterations in which they try to enter a CS. When using an unfair spinlock, in the worst case (at least in theory) every thread could enter the CS n/t times in a row instead of alternating with lock acquisition between threads. In certain scenarios this can boost throughput considerably, because the number of expensive cache line invalidations is reduced. However, the time until any other thread may enter the CS rises. In theory this can lead to starvation. In practice the cache coherency protocol should ensure that no starvation occurs.
Typically, the performance of fair spinlocks drops extremely when the number of threads competing for the same lock is greater than the number of CPU cores in the system. The reason for this is that the thread which is next in the sequence to acquire the lock might be sleeping. In contrast to unfair spinlocks, during the time the next thread is sleeping no other thread can acquire the lock because of the strict acquisition order guaranteed by the fair lock. This property is sometimes referred to as preemption intolerance.
Memory footprint
Generally, the required memory to store l spinlocks can depend on the number of threads t which are using the lock. While some spinlock implementations require only constant memory for t threads, other’s memory footprint scales linearly with the number of threads. The amount of needed memory to store a spinlock mostly doesn’t matter, because the memory footprint for the majority of locks is in the order of a few dozen bytes per thread. Mostly it’s a multiple of the CPU’s cache line size to account for false sharing. However, there are cases where the memory footprint plays an important role. Examples are extremely memory-constrained environments or applications that require vast amounts of spinlocks e.g. for fine-grained locking of lots of small pieces of data.

Pingback: Test-and-set spinlocks | The Infinite Loop